XSweet Core
The purpose of XSweet Core is to extract the underlying XML from Word documents (.docx) into valid, clean, and reusable HTML. XSweet Core extracts and saves “important” information from the .docx, such as:
- Font type and size
- Formatting, including bold, italic, underlining, text justification (left, right, center), subscript/superscript, etc.
- Paragraph indentation
- Endnotes and footnotes
- Outline and list levels
After initially extracting selected information, XSweet Core removes the (voluminous) extra noise in the XML, combines similar tags, abstracts away inline or repetitive formatting where possible, and rewrites word-specific feature implementations for HTML (e.g. notes, lists).
From an inscrutable mess comes good, clean, and human readable HTML.
Contents
Pipeline
Initial extraction is achieved by running the docx-extract/EXTRACT-docx.xsl sheet, which in turn runs the following sequence of steps:
docx-extract/docx-html-extract.xsl- which also runs
docx-extract/docx-table-extract.xsl
- which also runs
docx-extract/handle-notes.xsldocx-extract/scrub.xsldocx-extract/join-elements.xsldocx-extract/collapse-paragraphs.xsl
Running the EXTRACT-docx.xsl sheet has exactly the same effect as running these five sheets in sequence, using each step’s output as the input for the next.
Next, list-promote/PROMOTE-lists.xsl creates HTML representations of lists.
The math sheet, xsweet_tei_omml2mml.xsl captures math and equations added in Word.
Finally, run html-polish/final-rinse.xsl for additional cleanup to the HTML file.
Note that the outputs of all of these steps technically produce XHTML, not true HTML. This is expedient for chaining transformation steps into a pipeline. You may want to serialize to HTML5 as the final step (see html5-serialize.xsl, although it is not recommended to do so until all other desired transformations are finished.
Initial extraction
docx-html-extract.xsl
This sheet does the heaving lifting of extracting information from the MS Word XML. Contents are extracted from the body of the .docx. Information from headers and footers is not currently extracted.
File structure
The contents of the HTML body section are wrapped in the following section containers:
<div class="docx-body">: the main content of the file<div class="docx-endnotes">: wraps all endnotes<div class="docx-footnotes">: wraps all footnotes
Formatting
There is a surprising amount of redundant and conflicting information in Word’s XML, so it’s important to choose the right level from which to extract properties. Many properties can be specified either on the paragraph level or the text run level.
XSweet extracts the following properties from the paragraph-level (from inside <w:pPr> paragraph properties tags):
- Named Word styles
- MS Word outline level
- MS Word list level
Other formatting information specified on the paragraph level is ignored, as it is unreliable and often overridden by properties specified on the text run level (<w:rPr>). The following are extracted from the run level:
- Font family
- Font size
- Text alignment
- Font color
- Italicization, bolding, underline, sub- and superscript
Unless formatting in Word is achieved by applied styles (see below), formatting is extracted inline or as element-level CSS (<p style="[formatting]">).
Inline elements preserved in HTML:
- Bold
<b> - Italic
<i> - Underline
<u> - Subscript
<sub> - Superscript
<sup> - Line breaks
<br>
CSS properties captured include:
- font
font-family - font size
font-size font-weight:bold,normalfont-style:italic,normaltext-decoration: underline,nonefont-variant:normalorsmall-caps- text alignment
text-align:left,right,center - indentation
text-indent,padding-left,padding-right - margins
margin-top,margin-bottom,margin-left,margin-right - color
color
The following pseudo-properties are also extracted:
- list level
-xsweet-list-level: used for list extraction - outline level
-xsweet-outline-level: used to aid in heading detection
Be aware that XSweet extracts only what information is present in the Word XML. Some information, such as font type and size, etc., is not always explicitly defined in the XML. Word applies formatting from the default Normal style when no other style is specified. This can lead to some minor formatting inconsistencies.
Word styles
Word styles are referenced by name inside the Word file’s main document.xml file, and defined in the styles.xml file in the same directory, which contains style formatting and property information. XSweet’s initial extraction captures applied Word styles as CSS class attributes, and extracts the relevant information from styles.xml into a CSS <style> tag in the HTML <head>:
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta charset="UTF-8" />
<style type="text/css">
.Title {
;
/* Normal*/
font-family: Arial Unicode MS;
/* Title*/
margin-bottom: 0pt;
text-align: center;
font-family: Times New Roman;
font-weight: bold;
font-variant: small-caps
}
</style>
</head>
<body>
<div class="docx-body">
<p class="Title" style="font-family: Times New Roman; font-variant: small-caps; font-weight: bold; margin-bottom: 0pt; text-align: center">Chapter Two</p>
...
Note that formatting information is often repeated: both inline as style and from class - there is analytical value to having the CSS inline (e.g. for heading promotion.
Links
Where they exist, hyperlinks from the Word document are preserved and passed through to the HTML as <a href>s. Link text formatting is preserved.
<a href="https://www.nytimes.com/">
<span style="color: #0000FF; text-decoration: underline">
<span class="Hyperlink">https://www.nytimes.com/</span>
</span>
</a>
Internal-to-Word bookmarks are also extracted, although without additional processing (not provided by XSweet), they are merely placeholders and are removed during Editoria Typescript.
<a class="bookmarkStart" id="docx-bookmark_0">
<!-- bookmark ='_GoBack'-->
</a>
<a href="#docx-bookmark_0">
<!-- bookmark end -->
</a>
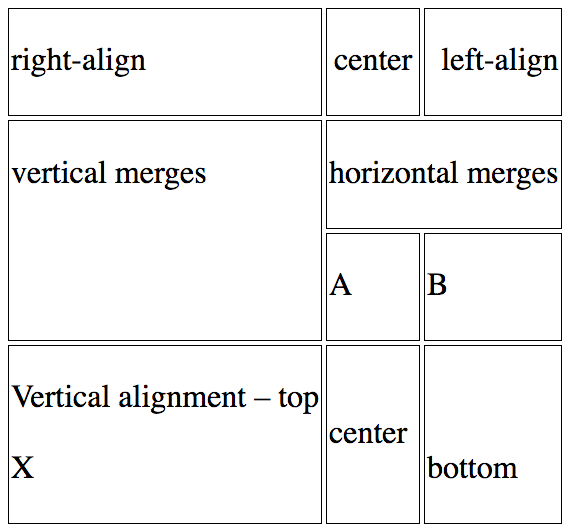
Tables
Tables are created by the docx-table-extract.xsl sheet. This sheet is invoked from inside the docx-html-extract.xsl sheet. It recreates Word tables in HTML, capturing:
- horizontal and vertical cell text alignment
- horizontally and vertically merged cells
Word table:

HTML recreation:
Download the HTML table code here: table-demo.html
Notes
In the handle-notes.xsl step, both endnotes and footnotes are added to the end of the HTML document and linked to the note callouts in the text. Notes come from the MS Word document’s endnotes.xml and footnotes.xml files.
Endnotes and footnotes are indexed separately. Endnotes are listed first, referenced as sequential integers. Footnotes are ordered as alphabetical callouts (a-z, aa, ab, etc.), and listed at the end of the HTML file after endnotes.
Endnote and footnote references are normalized and dynamically ordered by this step, by order of appearance. For example, even if the first endnote in Word references is labeled “2”, the converted HTML will renumber it to “1”. Notes that are never referenced in the text are removed.
Endnotes are placed inside a <div class="docx-endnotes">. Footnotes are placed inside a <div class="docx-footnotes">. The extracted syntax is as follows:
<div class="docx-endnotes">
<div class="docx-endnote" id="en1">
<p class="EndnoteText">
<span class="EndnoteReference">
<span class="endnoteRef">1</span>
</span> endnote</p>
</div>
</div>
<div class="docx-footnotes">
<div class="docx-footnote" id="fn1">
<p class="FootnoteText">
<span class="FootnoteReference">
<span class="footnoteRef">a</span>
</span> footnote</p>
</div>
</div>
The above code is the result of the docx-extract/handle-notes.xsl step. In the initial extraction, the < span class="endnoteRef"> and <span class="footnoteRef"> are left empty. The handle-notes.xsl step assigns each note sequential references.
Images
The initial extraction sheet (docx-extract/docx-html-extract.xsl) will insert image references to the location of the unzipped file. This feature relies on image files being available locally, with paths assembled assuming you’ve used the XSweet_runner_scripts and have left the source files and unzipped .docx directory in their original location.
Further cleanups
docx-extract/scrub.xsl
Previous steps generally pass elements through, even if they haven’t seen them before. This step removes these extra tags as unhelpful for our purposes unless they are explicitly caught and passed through. Examples of tags removed include:
- position
- iCs
- lang
- vertAlign
- noProof
- kern
Empty inline elements are removed, as is formatting applied to whitespace only, such as tabs and spaces. CSS style properties are normalized and put in a consistent order.
docx-extract/join-elements.xsl
This step combines strings of elements into one element when:
- More than one element of the same type occurs in a row, and
- The two tags have similar style attributes
This step does not combine runs of <div>s, <p>s, or <tab>s.
Example:
<p style="text-align: center">
<b>Part I: </b><b>United</b><b> and </b><b>Divided</b>
</p>
becomes
<p style="text-align: center">
<b>Part I: United and Divided</b>
</p>
docx-extract/collapse-paragraphs.xsl
In this step, inline formatting gets copied to the paragraph level wherever possible. Elements that contain only formatting information that can be expressed on the paragraph level are removed after the formatting has been moved (see the span in the example below). Example:
<p style="color: blue"><span font-weight: bold>blue bold text</span></p>
becomes
<p style="color: blue; font-weight: bold">bold blue text</p>
Note that inline styling information isn’t removed even if it is copied to a higher level. This allows maximum flexibility for further transformation, at the cost of a bit more “noise” in the HTML.
Lists
Lists are promoted according to the xsweet-list-level property, extracted from the MS Word <w:ilvl w:val=[integer]> property. Each list item becomes a <li> with a <p> inside it. XSweet currently extracts all lists as unordered lists.
PROMOTE-lists.xsl
A wrapper that runs mark-lists.xsl then itemize-lists.xsl in sequence
mark-lists.xsl
Wraps elements that have the xsweet-list-level property in a wrapper to mark them as lists, grouping and nesting according to xsweet-list-level value.
itemize-lists.xsl
Adds the <ul> and <li> wrappers to the lists marked by the previous step.
Example
mark-lists.xsl input:
<p class="ListParagraph" style="margin-left: 36pt; xsweet-list-level: 0">top-level list item</p>
<p class="ListParagraph" style="margin-left: 36pt; xsweet-list-level: 1">nested list item</p>
mark-lists.xsl output:
<xsw:list xmlns:xsw="http://coko.foundation/xsweet" level="0">
<p class="ListParagraph" style="margin-left: 36pt; xsweet-list-level: 0">top-level list item</p>
<xsw:list level="1">
<p class="ListParagraph" style="margin-left: 36pt; xsweet-list-level: 1">nested list item</p>
</xsw:list>
</xsw:list>
<p/>
itemize-lists.xsl output:
<ul>
<li>
<p class="ListParagraph" style="margin-left: 36pt; xsweet-list-level: 0">top-level list item</p>
<ul>
<li>
<p class="ListParagraph" style="margin-left: 36pt; xsweet-list-level: 1">nested list item</p>
</li>
</ul>
</li>
<p/>
See also the documentation for plain text numbered list detection.
Math
xsweet_tei_omml2mml.xsl
XSweet captures equations created with Word’s built-in equation tool (Office MathML format) and passes them through to the HTML as standard MathML. This features should “just work” with MS Word-native equations.
Not all browsers treat MathML exactly the same, but Javascript libraries such as MathJax can be used to standardize equation appearances. Also note that math in Word comes in many formats, not all of which are supported (LaTeX, MathType, images, etc.).
Math in Word:
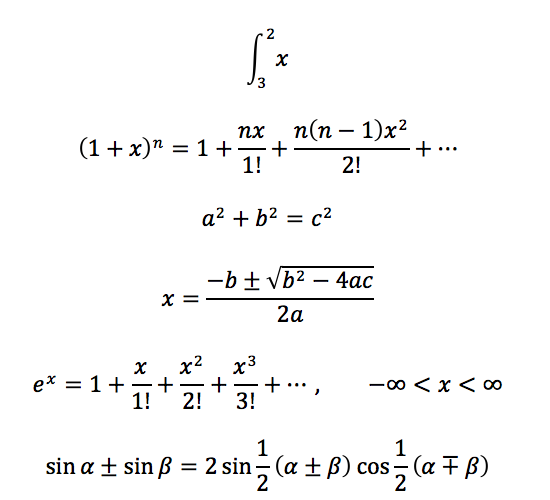
Extracted MathML in Firefox:
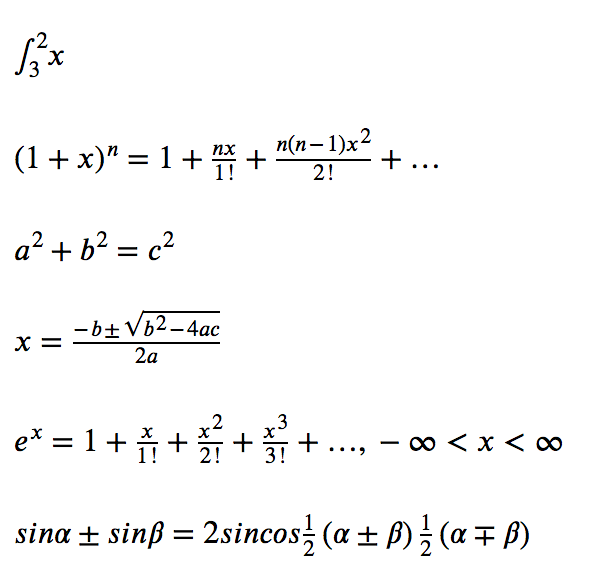
Final Rinse
html-polish/final-rinse.xml
The last step in the XSweet pipeline targeting HTML (except serialization to HTML if desired):
- Removes redundant inline tags (e.g.
<b>,<i>,<u>) that are expressed instead as CSSstyleattributes - Inserts placeholder comments into empty
<div>s and<p>s to ensure they are retained - Removes extraneous noise from endnote and footnote references
- When possible, removes redundant styling repeated on child elements
Additional XSL sheets
css-abstract
An XSL sheet that attempts to abstract style information specified on HTML tags into classes with similar formatting. This sheet is experimental and not actively maintained. For our purposes, it turns out having style information specified at a lower level enables much better analysis in other steps (e.g. heading promotion).
html-analysis.xsl
This sheet produces an analysis of the HTML document, including a tree structure and a count of the HTML elements.
Serialization
html-polish/html5-serialize.xsl
Serializes an input into valid HTML5. The primary benefit is to help normalize errors that may have occurred in the conversion wherever possible. For example, this can catch orphaned closing HTML tags without an opening counterpart and insert one, preventing errors.
html-polish/xhtml-serialize.xsl
serializes an input using XML syntax and HTML tags, nominally XHTML. As such it is syntactically well-formed, “standalone”, and suitable for further processing using an XML parser (although not necessarily valid to any particular XHTML schema).
produce-plaintext/plaintext.xsl
This step simply reads an HTML or XML file in and output the contents as plain text.